메뉴명을 받으면 카테고리 유사도에 따라 음식을 추천해 주고, 사용자의 평가를 받아 추천에 반영하는 컨텐츠기반 추천 시스템을 만드는 것이 목표이다 !!
우선은 공공 데이터 중 한국국제교류재단_한국음식정보_영문 데이터셋을 사용했다
AI hub에 있는 데이터셋들은 음식 이미지 데이터셋이라 이미지명에서 카테고리와 음식명을 뽑아와야 해서 텍스트로 제공해 주는 데이터셋을 선택했다
한국국제교류재단_한국음식정보_영문_20230228
해당 데이터는 재료(면, 떡, 채소류, 젓갈 등) 및 조리법(찜, 구이, 조림, 등) 별로 분류한 약 700여가지의 한국음식에 대한 정보를 영문으로 제공합니다.
www.data.go.kr

아래는 노션에 정리해 둔 데이터셋 후보들 💤
추천 시스템을 처음 접해보는 거라 기본적인 것부터 시작 !
우선 csv 파일을 읽기 위해 pandas를 임포트 해준다
import pandas as pd
df = pd.read_csv('food_list.csv',encoding='cp949') # csv 파일 읽어오기
data = df[['구분', '음식명']] # 필요한 데이터만 가져오기한글이 깨지기 때문에 인코딩 옵션을 추가해주었다
다음으로는 문자열로 되어있는 음식 카테고리를 벡터화해준다
sklearn 모듈 임포트 !
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(ngram_range=(1,1))
cv_category = cv.fit_transform(data['구분'])
cv.vocabulary_ # 카테고리별 인덱스 번호CountVectorizer는 텍스트에서 등장 횟수를 카운팅 하여 벡터화해 주는 역할을 한다
단순히 카운트만을 해주어서 빈도수를 기반으로 중요한 단어들을 뽑아주는 TF-IDF를 많이 사용한다는데, 나는 문장을 분석해서 벡터화하는 것이 아니라서 CountVectorizer를 사용하기로 했다 (CountVectorizer는 조사나 관사를 중요하게 처리하는 경우도 있다고 함)
여기서 ngram_range는 단어 묶음의 범위를 설정해준다
나는 (1, 1)로 설정해 주었는데, 내가 사용하는 데이터는 띄어쓰기 없이 한 단어묶음으로 되어있기 때문에 1개의 단어묶음 ~ 1개의 단어묶음으로 설정해주었다
CountVectorizer로 객체를 만들어주고 fit_transform을 통해 변환시켜준다
vocabulary_에는 카테고리별 인덱스 번호가 저장된다
다음으로는 벡터화된 카테고리의 유사도를 계산해준다
나는 코사인 유사도를 사용하였다
from sklearn.metrics.pairwise import cosine_similarity
similarity_category = cosine_similarity(cv_category, cv_category).argsort()[:,::-1]
print(similarity_category)
similarity_category.shape코사인 유사도를 구하고 argsort로 유사도가 높은 순서대로 정렬해주었다
다음으로! 메뉴명을 입력하면 비슷한 카테고리의 음식을 추천해주는 함수를 작성한다
def recommend_menu(df, menu_name, top=10):
target_menu_idx = df[df['음식명'] == menu_name].index.values
sim_idx = similarity_category[target_menu_idx, :top].reshape(-1)
sim_idx = sim_idx[sim_idx != target_menu_idx]
result = df.iloc[sim_idx]
return result입력된 음식명과 비슷한 메뉴를 뽑기 위해 해당 음식명의 정보를 가져온다
코사인 유사도가 비슷한 것들을 가져오고
자기 자신과는 코사인 유사도가 같기 때문에 제외해준다
data frame으로 만들고 결과를 반환해준다
결과를 출력해 봅시다~
recommend_menu(data, menu_name='입력하고 싶은 메뉴명')따란 ~
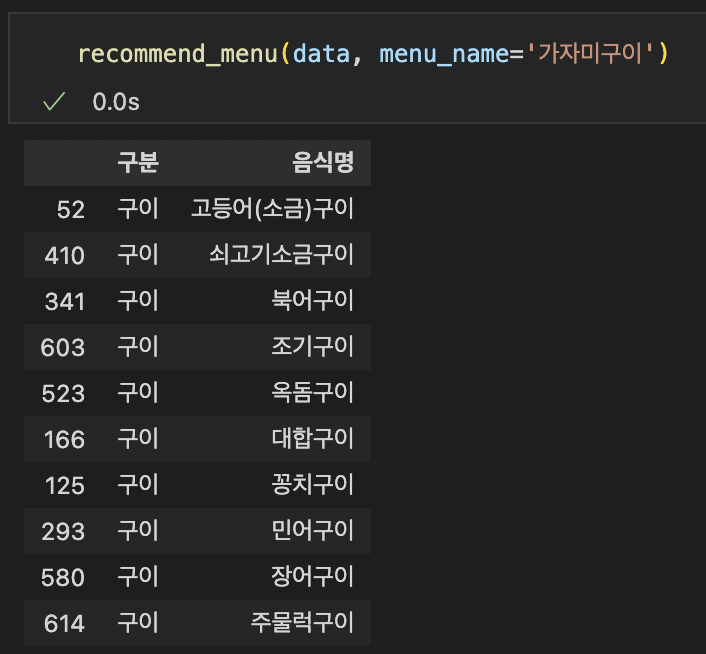

어떤 메뉴는 구분대로 엄청 잘 나오고 어떤 메뉴는 씁.. 더 공부해봐야겠다!! 🐈⬛🍧

's t u d y . . 🍧 > 이것저것' 카테고리의 다른 글
| [chatGPT] chatGPT API 사용하기 🫧 (0) | 2023.04.14 |
|---|---|
| [추천 시스템] 메뉴 추천 시스템 (3) (0) | 2023.04.11 |
| [추천 시스템] 메뉴 추천 시스템 (2) (0) | 2023.03.28 |
| 깃,,, 당신,,, 도대체 뭐야,, (0) | 2020.12.21 |
| 깃허브 시작 (0) | 2020.12.21 |